
A crew opens the pavement outside your building for a routine utility job. Thirty minutes later, your payment terminal is down, your phones are spotty, your staff can't access cloud files, and customers are standing at the counter waiting for answers. Nothing burned. No hacker made the news. But your business is still partially offline.
That's the reality most continuity plans miss. The disruption doesn't have to look dramatic to do damage. It only has to stop the few things your business depends on every hour of the day.
That's why business continuity planning matters. At its simplest, it's the discipline of deciding how your business will keep operating when a critical function breaks. It covers people, systems, vendors, communications, data, and the practical workarounds that keep revenue moving while you recover.
For smaller teams, the challenge is often getting started without overcomplicating it. A straightforward resource on BCP for small businesses can help frame the basics, but its core value comes from turning that idea into tested procedures your team can use under pressure.
A continuity plan on paper is not resilience. A continuity plan that's been tested, updated, and supported by the right technology stack gives you a fighting chance when something goes wrong. That's the difference this guide focuses on.
Introduction When the Unexpected Happens
Most businesses don't fail continuity in a dramatic, movie-style disaster. They fail in ordinary operational breakdowns. Internet drops. A server won't boot. A cloud app goes down. A key supplier misses a shipment. Someone with the only admin password is on vacation.
Those moments expose whether the business has a real operating plan or just a binder full of good intentions.
Practical rule: If your team has to invent the response during the outage, you don't have a continuity plan yet.
The strongest business continuity planning starts with a simple question. If one key function stops today, what happens in the next hour? Not next quarter. Not after a consultant workshop. Today.
That's how experienced operators approach resilience. They don't begin with broad statements about disasters. They begin with the practical choke points. Can we serve customers? Can we process payments? Can our team communicate? Can we access current data? Can we work from somewhere else if this location is unavailable?
When you answer those questions candidly, gaps show up quickly. That's useful. It gives you something concrete to fix.
What Business Continuity Planning Really Is
A lot of companies still treat business continuity planning like a list of bad events. Fire. Flood. Cyberattack. Storm. Power outage. That approach feels organized, but it often breaks down in real conditions because the event itself is less important than the effect it causes.
If the result is the same, your response should be ready either way. A cut fiber line, a misconfigured firewall, and an ISP outage can all create the same business problem. Your team can't connect. Orders stop. Calls fail. Work stalls.

Plan for effects, not headlines
A good plan centers on impact. That means downtime, data loss, communication failure, facility loss, vendor unavailability, or loss of key staff access. Those are the conditions that interrupt operations.
This shift matters because many plans fail by being too specific in the wrong way. Data shows that 73% of organizations fail their BCPs by predicting specific disasters rather than planning for outcomes like data loss or downtime, and 68% of mid-sized businesses overestimate their ability to recover from unanticipated system failures because their plans lack manual workarounds and failover drills (Flexential).
Consider maritime operations. A competent captain doesn't prepare only for storms. The crew trains for engine failure, navigation loss, medical emergencies, and man-overboard incidents. The cause may vary. The required response has to be immediate and repeatable.
That same mindset works in business. If your CRM is unavailable, your team should know where customer contact information lives, how to log work manually, who approves temporary process changes, and how customer messages go out.
What works and what doesn't
What works:
- Function-based planning: Start with what must continue.
- Manual fallback procedures: Decide how work gets done when software is unavailable.
- Clear authority: Name who can activate alternate procedures.
- Technology alignment: Make sure your systems support remote access, backup communications, and failover.
What doesn't work:
- Disaster theater: Long plans built around dramatic scenarios nobody rehearses.
- Single-person knowledge: One employee knows the process, password, or vendor relationship.
- Untested assumptions: “We can always hotspot phones” or “the backup should work.”
- Vendor name lists without strategy: Contacts alone won't save a delayed supply chain or failed service partner.
If physical damage is part of your risk profile, especially in storm-prone regions, your continuity plan should also connect to operational recovery partners such as commercial restoration services in Florida. That isn't the whole plan. It's one piece of getting back to workable conditions faster.
A continuity plan should answer, “How do we keep serving?” before it answers, “What exactly caused the interruption?”
The 6 Stages of a Living Business Continuity Plan
Business continuity planning works best as a cycle, not a project with an end date. Operations change. Systems change. Vendors change. Staff turnover happens. If the plan doesn't move with the business, it gets outdated fast.
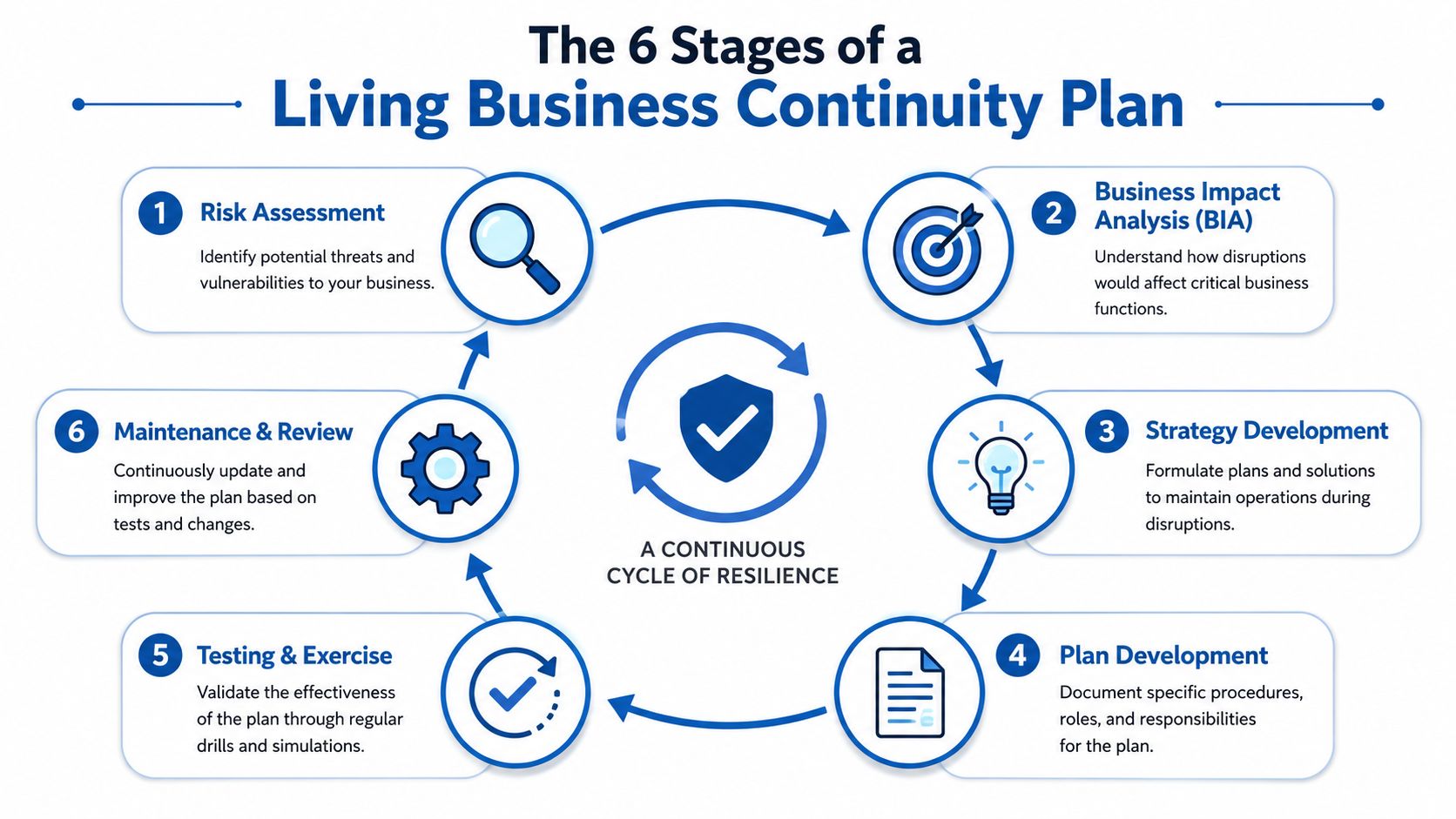
1. Risk assessment
Start by identifying what can interrupt operations. Look beyond natural disasters. Include internet failure, power issues, cloud outages, staff unavailability, hardware failure, ransomware, building access problems, and supplier breakdowns.
A useful risk assessment doesn't try to predict every twist. It looks for concentration risk. One internet circuit. One phone system admin. One payroll processor. One cloud storage location. One supplier for a critical part.
2. Business impact analysis
The plan becomes practical when a Business Impact Analysis, or BIA, identifies the functions that matter most and what happens if they stop.
Two terms matter here:
- RTO, or Recovery Time Objective: How quickly does this need to be back?
- RPO, or Recovery Point Objective: How much data can we afford to lose?
A simple analogy helps. If your accounting platform goes down, RTO is the answer to “how long can we operate without it?” RPO is the answer to “if we restore from backup, how far back can that data be before it becomes a serious problem?”
A rigorous BIA ties those decisions to real operations. Industry benchmarks show that organizations failing to define RTOs within 1–4 hours for core IT systems face a 60% higher risk of catastrophic financial loss during a disruption (TierPoint).
3. Strategy development
Once you know what must be protected, choose how you'll protect it. At this stage, trade-offs become unavoidable.
You may decide to use secondary internet access for critical sites, cloud-based phone systems for location flexibility, alternate vendors for key materials, or offline procedures for order intake when systems are unavailable. Not every process deserves the same level of redundancy.
A useful way to frame strategy decisions is this:
| Business function | If it fails | Acceptable workaround |
|---|---|---|
| Customer communications | Missed calls and delayed service | Route calls to mobile app or alternate line |
| Payments and invoicing | Revenue stops | Manual capture and later entry |
| File access | Staff idle time | Cloud backup or secured alternate repository |
| Core vendor fulfillment | Delivery delays | Secondary supplier and substitute workflow |
4. Plan development
Now document the procedures. Keep them short enough to use in a real incident.
Include:
- Activation criteria: What triggers the plan.
- Roles and backups: Who leads, who supports, and who steps in if someone is unavailable.
- Step-by-step runbooks: Clear instructions for each critical function.
- Communication templates: Internal staff notices, customer messages, vendor notifications.
- Access details: Where the plan, contacts, and credentials are stored securely.
Good documentation is boring in the best sense. It's direct, easy to scan, and written for stressed people making decisions quickly.
Later in the process, it helps to see the lifecycle explained visually and in another format:
5. Testing and exercise
A tabletop exercise often exposes weak plans, revealing that a team doesn't know who can approve failover, where vendor contacts live, or whether remote staff can access key systems from outside the office.
Test both the technology and the people. Simulate a phone outage. Disable access to a nonproduction system. Practice manual order entry. Ask the team to respond without warning.
The first test is supposed to be uncomfortable. That's how you find hidden dependencies before customers find them for you.
6. Maintenance and review
Treat the plan like an operating document. Review it after staff changes, new software deployments, office moves, major vendor changes, and any real incident.
The questions during review are simple:
- What changed in the business?
- What failed or almost failed recently?
- Does the current plan still match how work is performed?
If the answer to the third question is no, the document needs revision, not admiration.
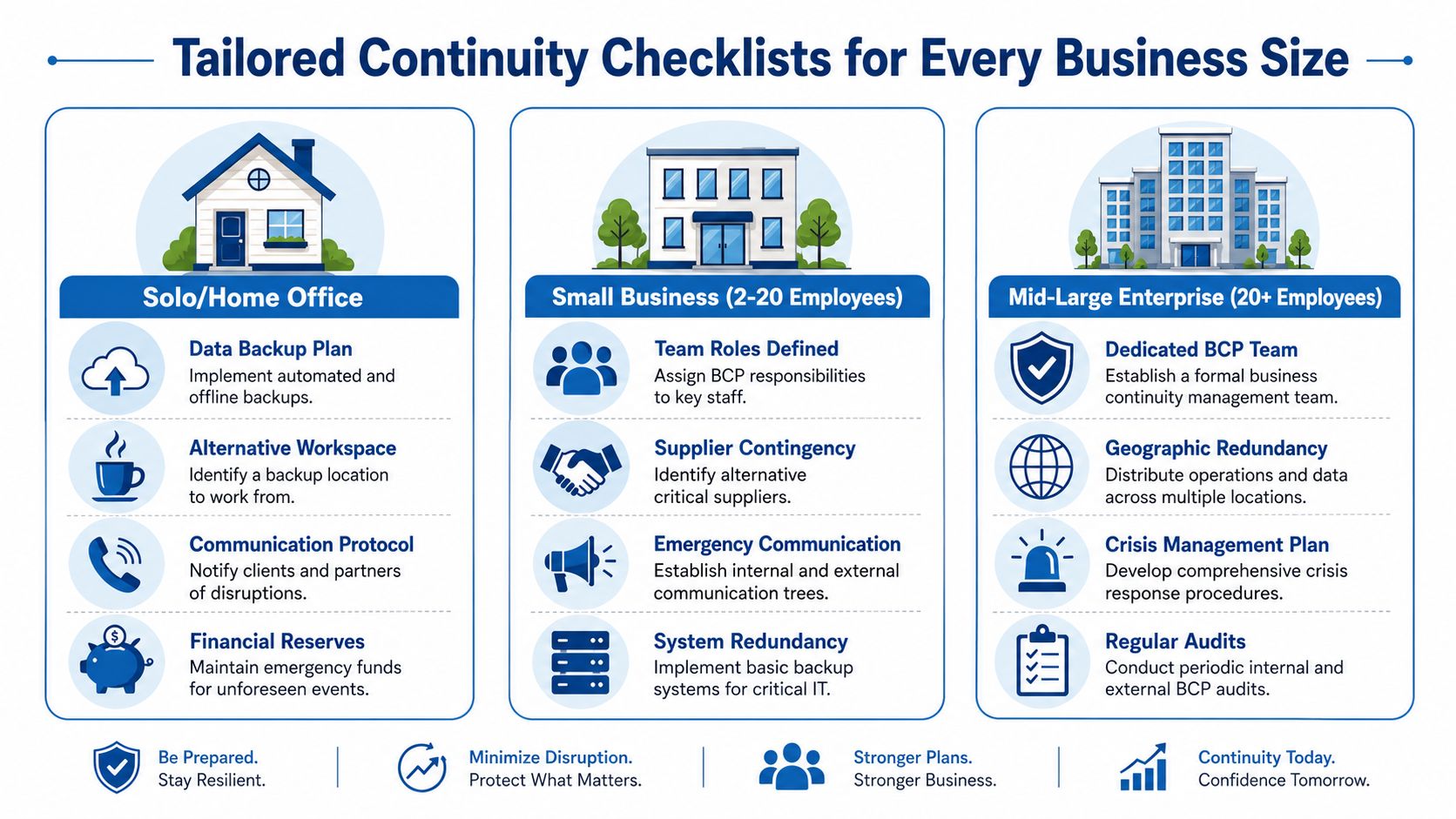
Continuity Checklists for Your Business Size
The right continuity plan for a solo consultant won't look like the right plan for a fifty-person distributor. That's normal. The goal is not to copy an enterprise template. The goal is to protect your own critical functions with the right level of structure.
One reason to keep these checklists grounded is that execution is where many organizations fall short. While 61% of businesses have a business continuity plan, more than 40% will not reopen after a disaster. Smaller businesses lose an average of $427 per minute during downtime, and only 30% of IT professionals report having a fully documented strategy (Invenio IT).
Solo and home office
If you run the business yourself, continuity planning is mostly about avoiding single points of failure in your workspace and data access.
- Backup connectivity: Have a secondary way to get online.
- Cloud file access: Keep current working files available off-device.
- Client communication plan: Save a ready-to-send message for delays or outages.
- Alternate workspace: Know where you can work if your home office is unavailable.
- Credential access: Store essential access details securely so you're not locked out during a device failure.
Small business with 2 to 20 employees
At this size, continuity depends less on one person and more on coordination. The weak point is often confusion. Everyone assumes someone else has the vendor list, knows the phone rerouting process, or can approve overtime during a disruption.
Use this checklist as a starting point:
- Role assignments: Name who owns communications, IT coordination, customer response, and vendor escalation.
- Contact tree: Keep current phone, email, and backup contact details for staff and key vendors.
- Manual workarounds: Decide how orders, scheduling, intake, and billing happen if primary systems are down.
- Basic redundancy: Add resilience where failure stops revenue. A good primer on network redundancy for business continuity helps explain where duplicate paths and backup links fit.
- Local copies of essentials: Keep accessible versions of critical procedures, forms, and customer-facing scripts.
Medium business with 21 to 100 employees
At this stage, business continuity planning has to become more formal. Informal knowledge sharing isn't enough. You need defined teams, clearer approval paths, and more disciplined vendor management.
A useful operating checklist includes:
| Priority area | What to have in place |
|---|---|
| Team structure | Named continuity lead, department backups, and escalation chain |
| Systems | Recovery priorities, dependency mapping, and access testing |
| Vendors | Alternate suppliers, lead-time assumptions, and service contacts |
| Communications | Internal alerts, customer messaging, and leadership updates |
| Facilities | Remote work options, site access alternatives, and equipment fallback |
Don't try to harden every process equally. Protect the functions that stop cash flow, customer service, and team coordination first.
These checklists aren't exhaustive. They're meant to move you from awareness to action. A short, tested plan for a handful of critical functions beats a polished document nobody has practiced.
Building Your Resilient Tech Foundation
Continuity plans fail when the underlying technology can't support the recovery strategy. Teams say they'll work remotely, but remote access isn't ready. They expect calls to follow staff to mobile devices, but the phone system can't do it cleanly. They assume backups are recoverable, but nobody has checked.
That's why resilient infrastructure belongs inside business continuity planning, not beside it.
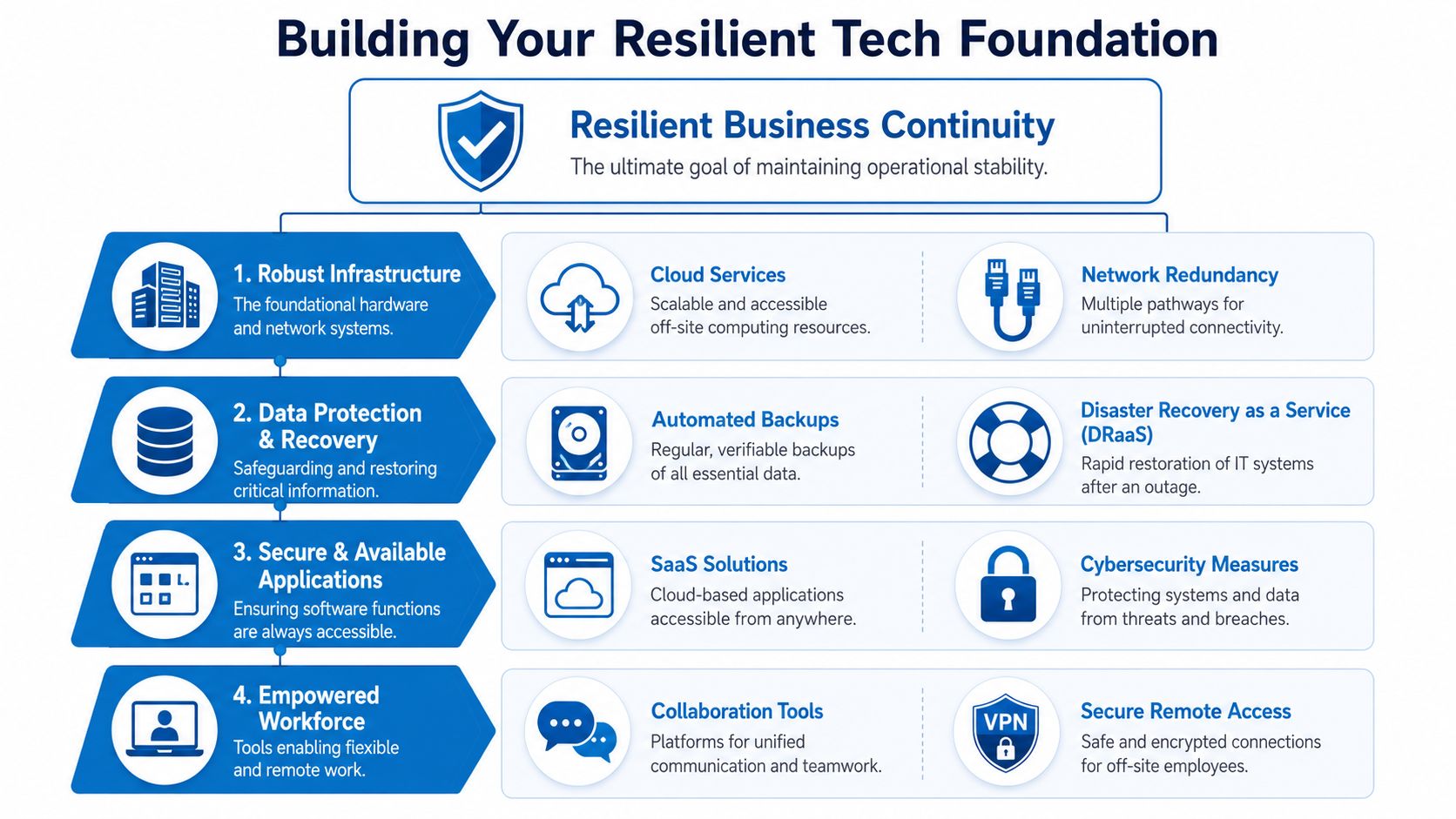
The four layers that matter most
A practical tech foundation usually comes down to four layers:
- Connectivity: Your primary and backup paths to the internet and cloud applications.
- Communications: Voice systems and collaboration tools that work from different locations.
- Security and access: Controls that let employees work safely during abnormal conditions.
- Recovery capability: Backups, restoration processes, and verified access to current data.
If one of those layers is weak, the rest of the plan gets shaky.
Technology choices that support continuity
Reliable internet is not just an IT utility. For many businesses, it's the path to payment processing, customer communication, inventory systems, cloud storage, and line-of-business apps. The same is true for hosted voice. If your office phones only work inside one building, your communication plan has a hard stop built into it.
Managed edge and security services matter for the same reason. A continuity response often requires quick policy changes, secure remote access, traffic visibility, and cleaner control over how systems fail over. Solutions such as managed network security services for business continuity can support that operational control when they're implemented with recovery in mind.
For organizations reviewing providers, Premier Broadband is one option that combines fiber connectivity, business internet, VoIP, and managed network edge services in a single environment. That kind of consolidation can simplify continuity planning because internet, communications, and security decisions affect each other directly.
Don't confuse backup with recovery
Many teams assume that having backups means they're covered. It doesn't. Backup answers whether data exists somewhere else. Recovery answers whether you can restore it fast enough, cleanly enough, and in a format the business can use.
If you ever need specialist help after device failure, a technical resource on how to recover data from a hard drive can be useful. But the better operational move is to design for recoverability before a drive fails, not after.
A backup that hasn't been tested is a hope, not a control.
The right foundation isn't flashy. It's dependable, documented, and aligned with how your people work when conditions are messy.
BCP in Action From Server Crash to Vendor Failure
A continuity plan only proves itself when something breaks.
In one common scenario, a small professional services firm loses access to a core file server on a busy morning. Staff can't pull current documents, intake slows down, and clients begin calling for updates. Because the team had already documented a manual intake process, moved key templates to an accessible cloud repository, and shifted calls through a mobile-friendly voice system, work continued in a reduced but controlled mode. The disruption was still painful. It just wasn't paralyzing. Their plan also depended on clear provider expectations, which is why reviewing items like business internet service-level agreements matters before an outage happens.
A different example shows why vendor planning belongs inside continuity, not in a separate procurement file. A growing agency depends on one outside provider for a critical production step. The vendor has an unexpected service interruption, deadlines start slipping, and clients want answers immediately. The firms that recover faster in that situation are usually the ones that have already named an alternate provider, defined a switch process, and cross-trained internal staff.
That approach isn't theoretical. With 82% of organizations reporting vendor failure as their top disruption risk, companies with documented secondary supplier lists and cross-trained staff recover 40% faster from vendor-induced disruptions (Travelers).
The point in both stories is the same. The plan didn't prevent the disruption. It reduced the operational shock. That's what good business continuity planning does. It gives the team a prepared path instead of forcing improvisation under pressure.
From Plan to Resilience Your Next Steps
The best continuity plans are rarely the longest. They're the ones people can use when stress is high and time is short.
If you take one lesson from all of this, let it be this. Plan for impact first. Downtime, data loss, communication failure, and vendor interruption are the business problems that need answers. Once those are covered, the specific event matters less.
A mature program also keeps testing. ISO 22301 is the global standard for Business Continuity Management Systems, and organizations that conduct annual DR plan testing achieve a 70% success rate in meeting RTOs, compared to 30% for those testing less frequently (Cloudian).
Start small if you need to. A useful first move is a short leadership meeting to identify your top three business functions and the maximum downtime each can tolerate. After that, review whether your current connectivity, communication tools, and security setup can support those recovery targets. If you're reassessing your core infrastructure, it helps to compare business internet solutions built for operational continuity.
Resilience isn't a document you finish. It's a capability you build, test, and keep current as the business changes.
If your business depends on reliable connectivity, voice systems, and secure network operations to stay running during disruptions, Premier Broadband is worth evaluating as part of your continuity strategy. Review your current internet, VoIP, and network setup against your recovery goals, then close the gaps before the next outage forces the issue.